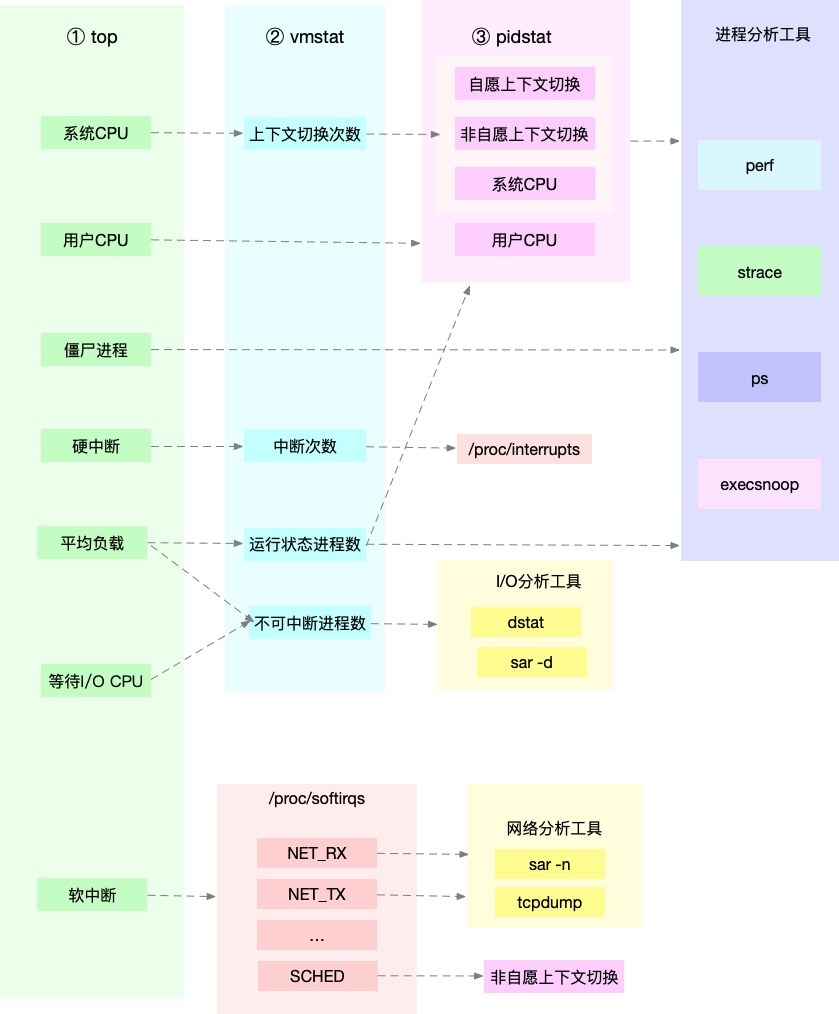
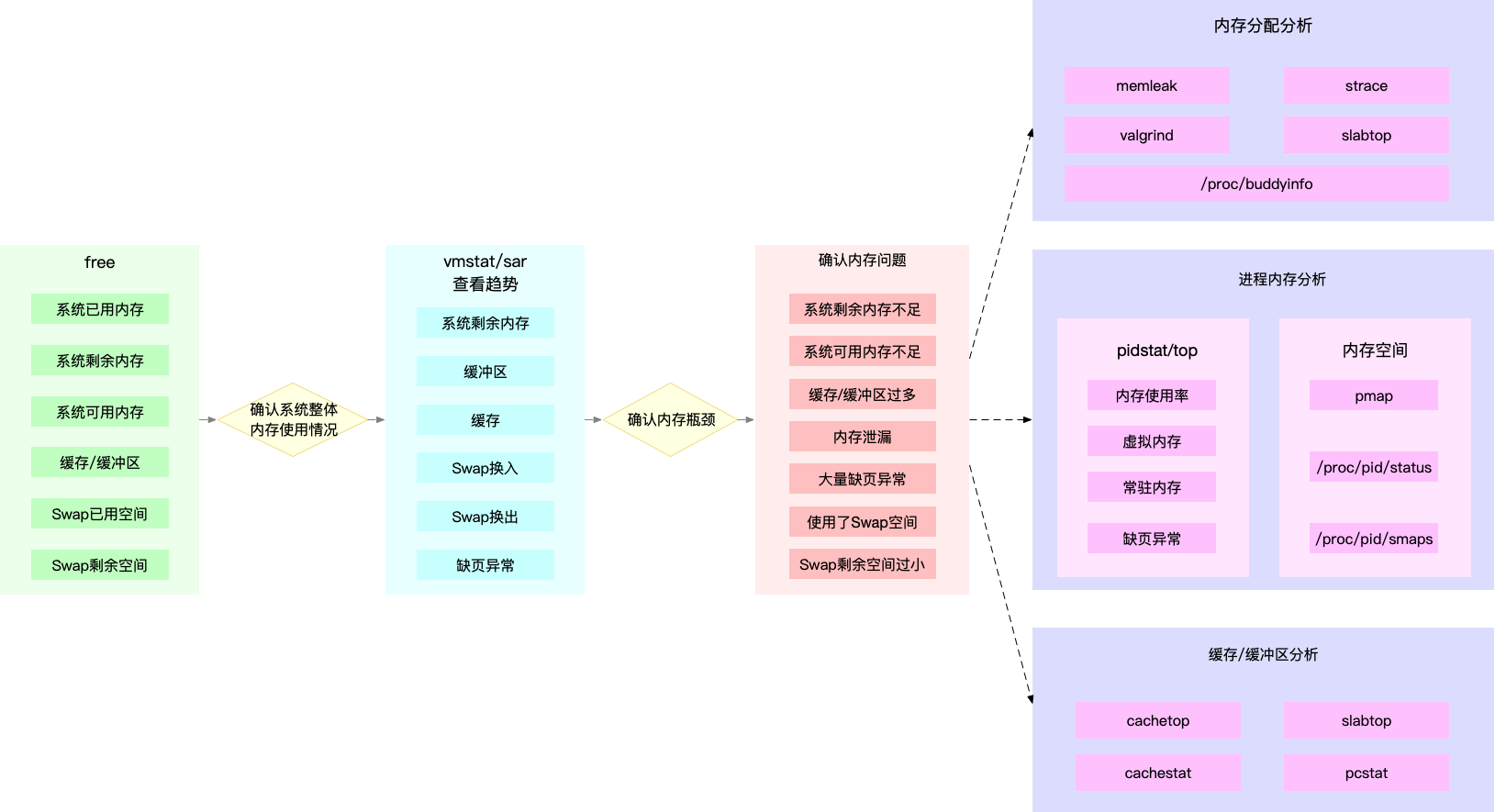
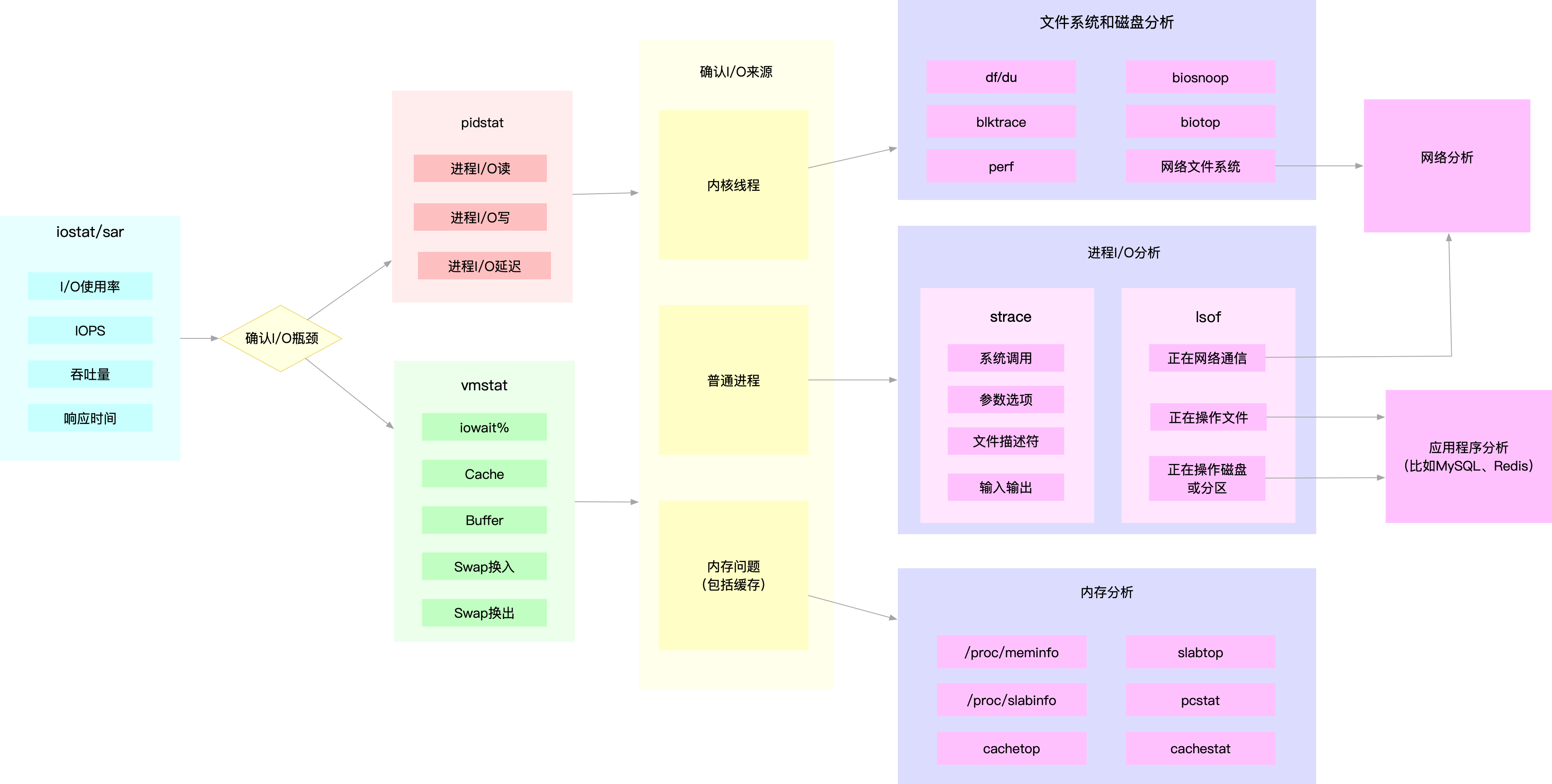
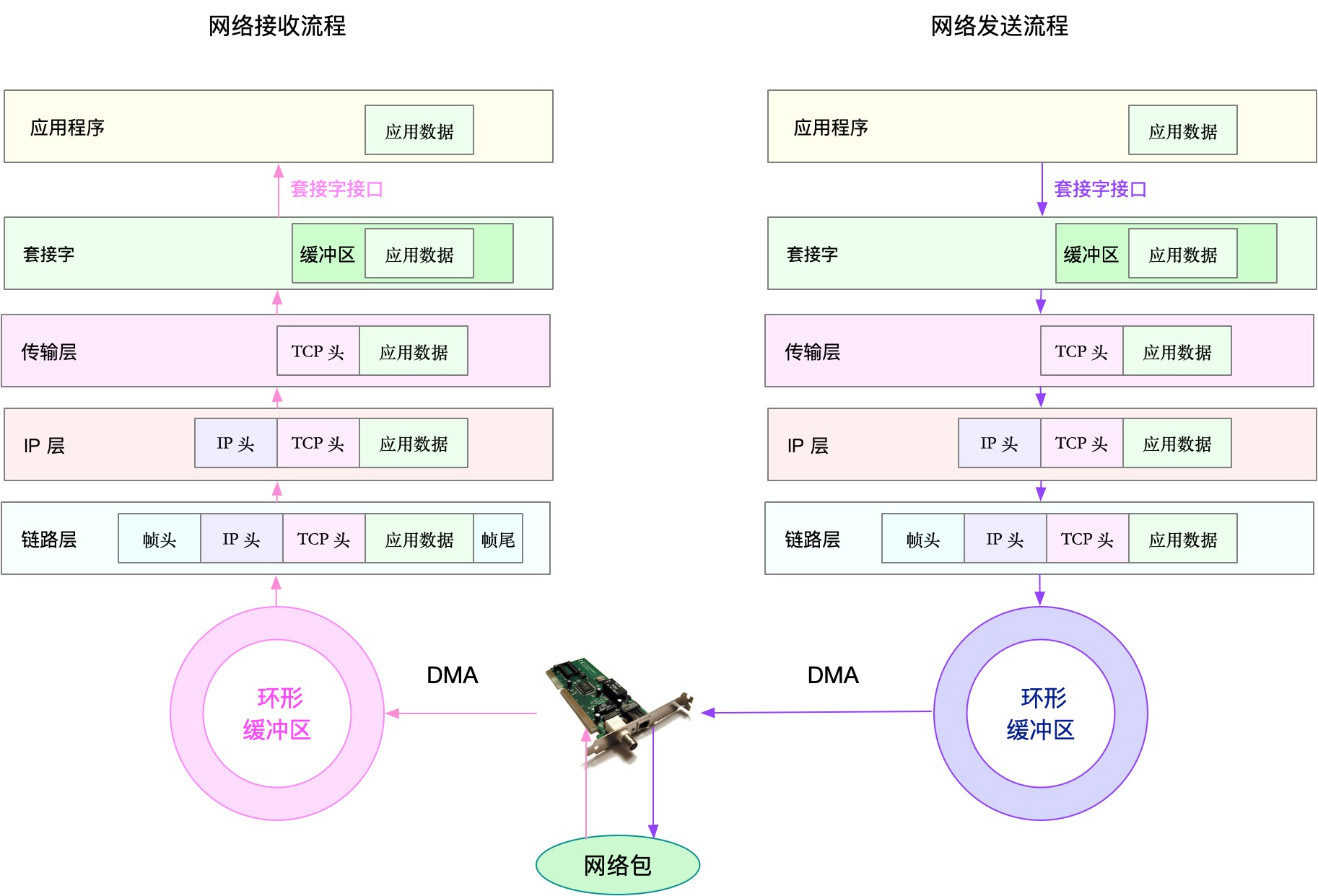
接口异步
当业务打到一定规模后,接口串行是性能的一大杀手,因为它:
- 影响用户体验:一个接口往往会至少调用3~5个甚至更多的服务,对于用户的访问会有极大的延迟。
- 降低系统吞吐:比如一个大的事务或者请求往往会长时间占用链接当业务高峰来了后会占用很多链接无法释放,导致请求排队。
接口的异步化往往是解决这种问题的利器,我们可以使用一些带有顺序消费能力的消息队列来解决这种问题。我们实际开发中往往是将一个大事务通过MQ等手段异步拆成多个小事务来增大并发。
分布式事务的数据一致性
分布式服务必然会带来数据一致性的问题,和事务的CAID相比,基本遵循俩个原则
CAP理论
C:一致性
A:高可用性
P:发生故障好,保证分区可用
分布式事务往往无法完全严格实现CAP,一般是保证P的基础上实现C、A。
BASE理论
是CAP的一种延展
BA:基本可用,对应的是降级
S:柔性状态,即允许当前数据存在中间状态,比如mysql同步时候各从库的数据可能不一致
E:最终一致性,即一段时间之后数据会达成最终一致
俩阶段提交
原始的分布式事务采用XA俩阶段提交。分为俩个接口:
- XT:客户端–>事务管理器,负责开始事务、提交事务、回滚事务
XA:一般是资源管理器和事务之间交互,比如回滚,提交等。
在这个协议下整个事务的流程是这样的:
- 客户端开启事务;
- 客户端操作事务中多个资源管理器(mysql)这时候数据已经持久化
- 客户端提交事务
- 第一阶段:prepare,事务管理器去轮询各资源管理器检查状态,返回 READY,NOT_READY,READY_ONLY,
- 第二阶段:commit or rollback,根据第一节阶段的结果进行rollbacck(NOT_READY)或者commit(READY)。
分布式系统–柔性事务
上面的方案在传统项目中是可以的,但是在互联网应用中,这种项目因为锁的存在会极大的降低性能。
通过日志来进行业务补偿
事务日志:记录事务的开始,事务参于者,状态。保存在事物管理器
undo/redolog:用于发生异常后为了实现最终一致性,进行重试( 正想补充 redolog ) 或者回滚 ( 反向补偿 undolog )
可靠消息传递
防止在网路错误时候出现消息丢失情况,我们要实现,at least once:即消息可能投递多次
主要幂等性:同一条数据执行多次后,结果不能发生改变。实现方案是采用排重表。【如:可能有多条插入数据库的消息,我们应该只能写入一条记录这种是幂等行,解决方案可能会采用一个排重列表,过滤掉重复的消息】
无锁设计
减少锁开销
- 表面事务回滚,没有回滚则没有锁
- 通过辅助表取代热点数据的修改。如,秒杀系统的库存的预减
- 乐观锁
阿里的实践
消息队列
具体叫rocketmq的实践,先发一个half-message给mq此时对消费者即远端事务透明,生产者完成本地事务提交给mq,mq在将事务发给消费者。
兜底策略:如果mq长期没有half-message的ack,mq会主动问询生产者状态,来确认事务是进一步进行还是丢弃。
缺点:仅适用于俩个参与者,仅能提供正向补偿。
TCC
为了解决多参与者以及实现反向补偿(rollback),在支付宝场景下实现了TCC(try confirm cancel)
- try:对资源的检验、锁定,实现软隔离
- confirm:事务的真正提交过程,只用try阶段锁定的资源。
- cancel:取消回滚
tcc只提供了框架,真正的资源回滚还需要业务方自己通过代码进行回滚。
TXC
新一大分布式事务处理框架,他是通过在db层上实现了比较薄的代理来实现分布式事物。
- TXC用来开启(register)一个事务,分配一个txid
- 之后所有的对db的请求会先通过txc-rm这个代理,他负责解析sql语句如果遇到Insert/delete/update会生成undolog和redolog
- 自动回滚:当有回滚需求时候
- 校验当前数据库的值和redolog是否一致,如果一致通过undolog回滚
- 如果不一致,说明别的进程和事务已经修改了数据库,这时候回滚可能会导致数据不一致,只能同构redolog进行重试补偿。
缓存的使用
以大促为例,阿里采用自己开发的Tair作为缓存,我们可以使用redis的方案。
以秒杀场景为例,看下缓存的作用:
首先要做服务集群的隔离
小库存的秒杀场景
- 商品详情页的缓存降低数据查询压力
- 库存校验的的条件判断:在下单前判断库存是否还足够
- 下单时候用乐观锁来修改库存
大库存热点商品的秒杀
这种情况不适合用乐观锁的原因是锁所冲突很大,并且会出现后下单的反而抢到了商品情况。
我们这时候在下单时候,可以按照如下逻辑,注意括号中的备注
预订单对用户不可见(用于缓存崩溃等情况恢复用的快照)–>发送消息给mq(保证下订单的顺序)–> 缓存中扣减库存(事务交给缓存)–>修改订单状态,完单。