mysql的锁
全局锁(FTWRL)
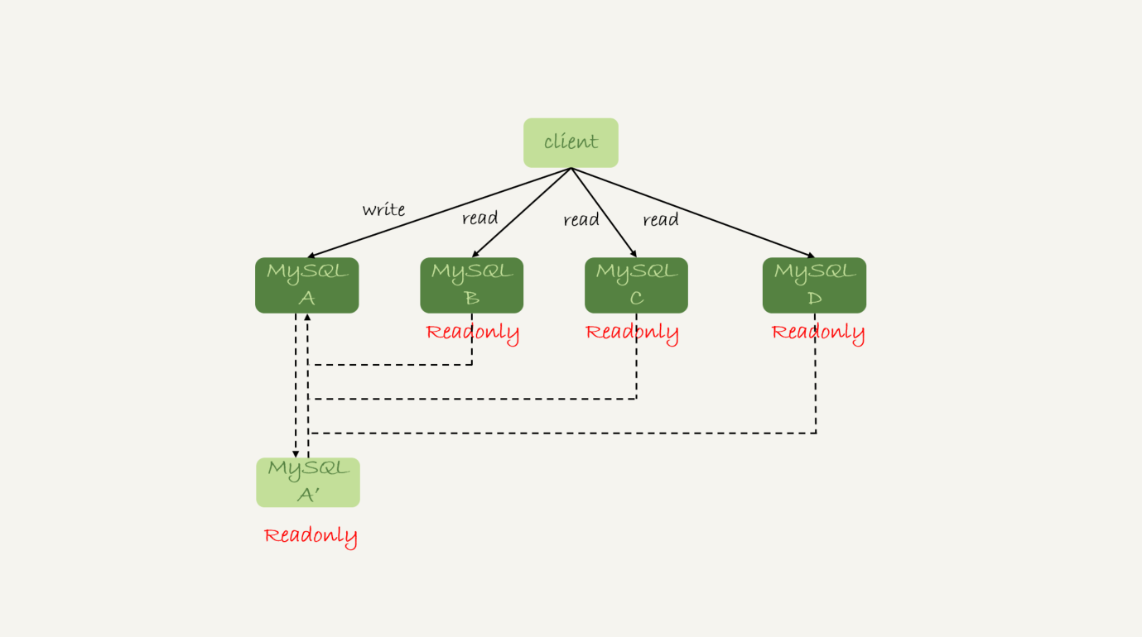
Mysql提供的针对数据库级别的对数据加读锁的功能:Flush tables with read lock。之后针对这个数据库的增删改、DDL、事物提交语句都会被堵塞住。他主要的用途是用于数据库全库的逻辑备份。
- 优点:
- 全局锁是数据库级别的,所有表引擎都支持,在数据的导出对库实例加锁,保持导出数据逻辑的一致性。
- 和设置数据库只读(set global readonly=true)相比,全局锁在当前链接异常或者中断的情况下可以自动释放,而设置数据库只读不能。
- 缺点:导出操作如果对数据库加锁,数据库的变更操作会被lock住,解决方案:对于Innodb引擎,可以用mysql自带的mysqldump工具使用参数–single-transaction.
表级锁
mysql的表级锁分俩种,一种是表锁,一种是元数据锁(meta data lock MDL)
表锁
预发是 lock tables … read/write。可以用unlock主动释放锁。也可以在链接中断时候自动释放。
表锁对于自己和其他线程读写操作的限制如下:如果对一个表进行read/write锁。其他线程在写or读/写时都会堵塞;同时本线程也只能读or读写该表,其他表无法访问。
元数据锁(MDL)
该锁不用显示的使用,在访问表的时候会自动加上,他用来保证访问数据时候数据表结构的稳定性,他有如下特点:
- 对一个表的数据CRUD时候,加MDL读锁;当修改表结构时候,加MDL写锁
- 读锁是不互斥的,因为这些操作不会该表结构,所以可以多个线程同时对表做CRUD;
- 读写锁之间,写锁之间是互斥的,也就是说当对表进行CRUD时候,为了保证返回数据的稳定性,DDL操作是堵塞的。
由于上面MDL的读写锁机制,就会有下面这种情况,修改一个访问量很高的小表,会导致整个库挂掉:
比如:
- 大量的select语句,加了MDL读锁,这时候是不会堵塞的;
- 这时候有一条alter表的语句需要执行,加了MDL写锁,开始block。
- 由于select量很大,alter会一直堵塞,这时候后续的select也会堵塞,很块连接池就被用完了。
解决方法:
MariaDB 已经合并了 AliSQL的方法
1 | ALTER TABLE tbl_name NOWAIT add column ... |
行锁
为了加强数据库的并发度引入的锁的机制,他有如下几个特点:
- 行锁是由mysql的表引擎决定,Innodb支持行锁,MyISM不支持行锁。
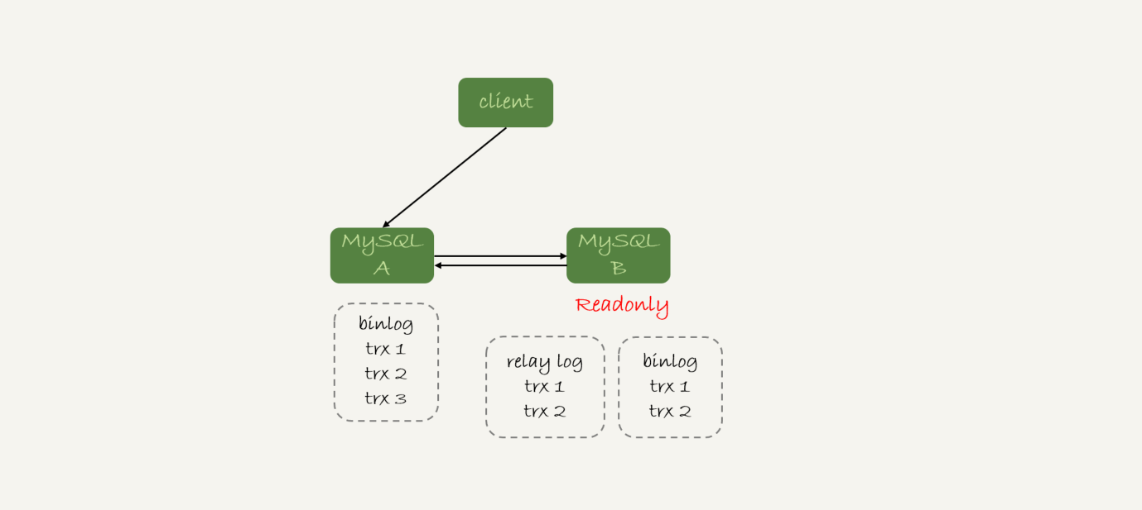
- Innodb的行锁是两阶段锁:即数据需要锁的时候对数据涉及到的行加锁;在事务结束后才释放行锁;
如何减少行锁的锁冲突
为了减少锁的冲突,我们在事务中要把会引起锁冲突的语句往后放。因为事务是原子性的所以,在一个事务中,要么都成功要么都失败,所以我们在一个事务中根据业务需求可以把一些没有锁冲突的操作或者语句放在事务的前面先只是,可能会造成锁冲突的语句放在后面,减少锁冲突加大并发。
死锁和死锁检测
- 出现原因:循环的资源等待。举个例子:俩个事务,事务1:用户uid=1点赞,事务2:用户uid=1取消赞。如下:这时候在并发时候可能会造成死锁当事务1、事务2都执行完第一条语句时候,这时候事务1等待事务2执行完第二条语句释放,这时候事务2执行完第二条语句等待事务一释放
1 | #事务1 点赞 |
- 解决方法
- 等待锁超时,用innodb_lock_wait_timeout来设置;(默认50s)
- 用死锁检查的方式innodb_deadlock_detect设置为on,表示开启,一旦发生死锁回滚死锁链条中的某个事务让其他事务可以进行;
死锁检查真的很美好么?
死锁检查是一个O(n*n)的时间复杂度的操作,因为每一个被堵塞的线程都会检查是否是自己导致了死锁。导致会有大量的线程做无谓的死锁检查,最终现象是CPU很高,但是并发度很低。
解决方案:
- 粗暴的做法:如果确定没有死锁情况,关掉死锁检查。
- 控制并发度:客户端自己控制,最多只有N个线程同时进行修改,但是不排除一个库有多个客户端(比如多连接池)
- 中间件开发:如果发现请求数据一样的,进行排队减少冲突。(成本高)
间隙锁(gap lock) 与幻读
什么是幻读?为什么会出现幻读?幻读有什么危害?
- 事物在RR隔离级别下;
- 一个事物中,俩次查询涉及的条件相同,后面的语句出现了之前查询没有存在的数据。(注意:出现了新增的数据);
- 为什么出现幻读:RR隔离级别下,当数据发生改变,采用当前读的原则
- 幻读的危害:破坏了业务的语意;违反了数据的一致性
为什么需要间隙锁?当数据库的隔离级别是RR的情况下,由于Mysql的行锁在为数据上锁的时候需要数据在表中,也就是说对于新插入的数据mysql是无法上锁的。这样就会出现幻读的情况。innodb为了解决幻读引入了间隙锁。
innodb是如何加间隙锁的
- 当一个涉及到为数据加锁的语句执行时候,会为涉及到的数据加行锁,同时为整个表的数据之间加间隙锁(gap lock),这个行锁+间隙锁也叫next-key-lock。
- 间隙锁是个左开,右闭的空间。比如一张表有如下数据
- 间隙锁只会锁插入语句,其他的操作是不互斥的。
具体例子说明
1 |
|
间隙锁的缺点
间隙锁也并不是万能的在某些情况下会造成死锁比如,下面的情况:
- 判断断C=5是否存在;
- 不存在就insert,存在就update;
- 图中在并发的情况下,且c=5不存在,行锁无效,触发间隙锁,这时候事物2的insert需要等待事物1commit之后释放间隙锁。
- 但是事物1,因为也insert导致了,不能释放锁就触发了死锁。
| 事物1 | 事物2 |
|---|---|
| begin transaction; | begin transaction; |
| select * from t where c=5 for update ; | select * from t where c=5 for share update; |
| select * from t where c=5 for update ; | select * from t where c=5 for share update; |
| - | insert into t values(5,5); |
| insert into t values(5,5);(dead lock) | - |
这种方式的解决方案,在满足业务的前提下,将事物的隔离级别改为RC,并且将binlog置为row。
innodb对于数据加锁的原则
Q:锁是加在数据上还是加载索引中?
A:锁是加载索引中。(因为Mysql的数据是在磁盘中的,而索引是在内存中切有序的。所以按照mysql的能用内存用内存的原则是锁索引的)
- 加锁的基本单位是next key lock;
- 查找到访问的对象会加锁;
- 对于查询等值唯一索引的数据加锁,会退化成行锁;
- 对于查询等值非唯一索引的数据加锁,当向右扫描到第一个不符合索引的数据时候,会退化成间隙锁;
- 注意:对于范围查找唯一索引,会访问到不满足条件的第一个值位置;
所以准确的说,innodb在对数据加锁不是简单的为涉及到的数据加行锁,而是对要访问的数据加一个nextKeyLock,然后innodb在根据如上条件判断哪些数据加行锁,哪些数据不是行锁是间隙锁;(确定是查询范围锁的数据是x锁,中间不存在的数据间隙锁)