MySql的主从切换
大部分业务数据库都是读多写少,我们在实际使用情况上往往会遇到读性能,本章主要讲述如何解决读延迟
一主多从的架构
我们一般会采取一主多从架构,主库承担所有的写和一部分读的任务,丛库根据承担读的任务。
如图: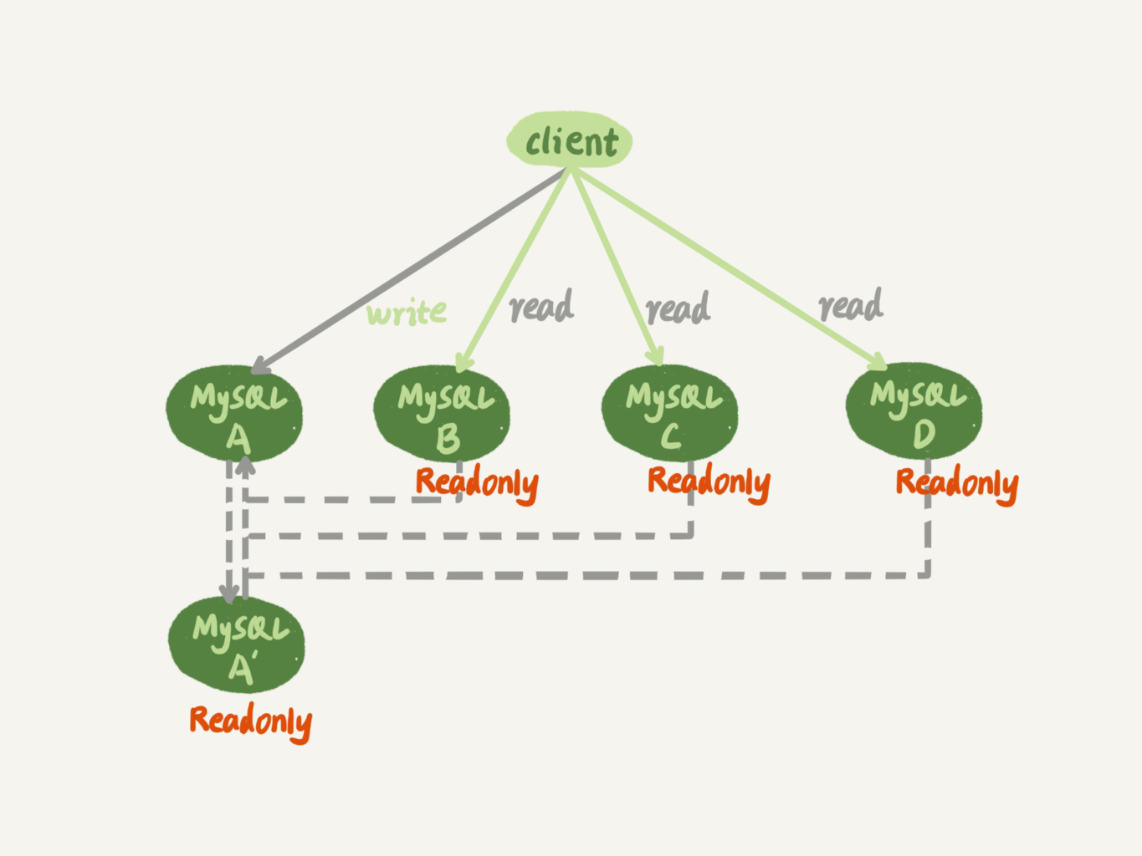
- A和A’互为主备
- B、C、D是A的从库
下面我们来通论下当主库A发生故障后,A’成为主库,BCD的主库也要都指向A’,下面我们来讨论下遇到这种情况,mysql是如何做主从切换的。
如图: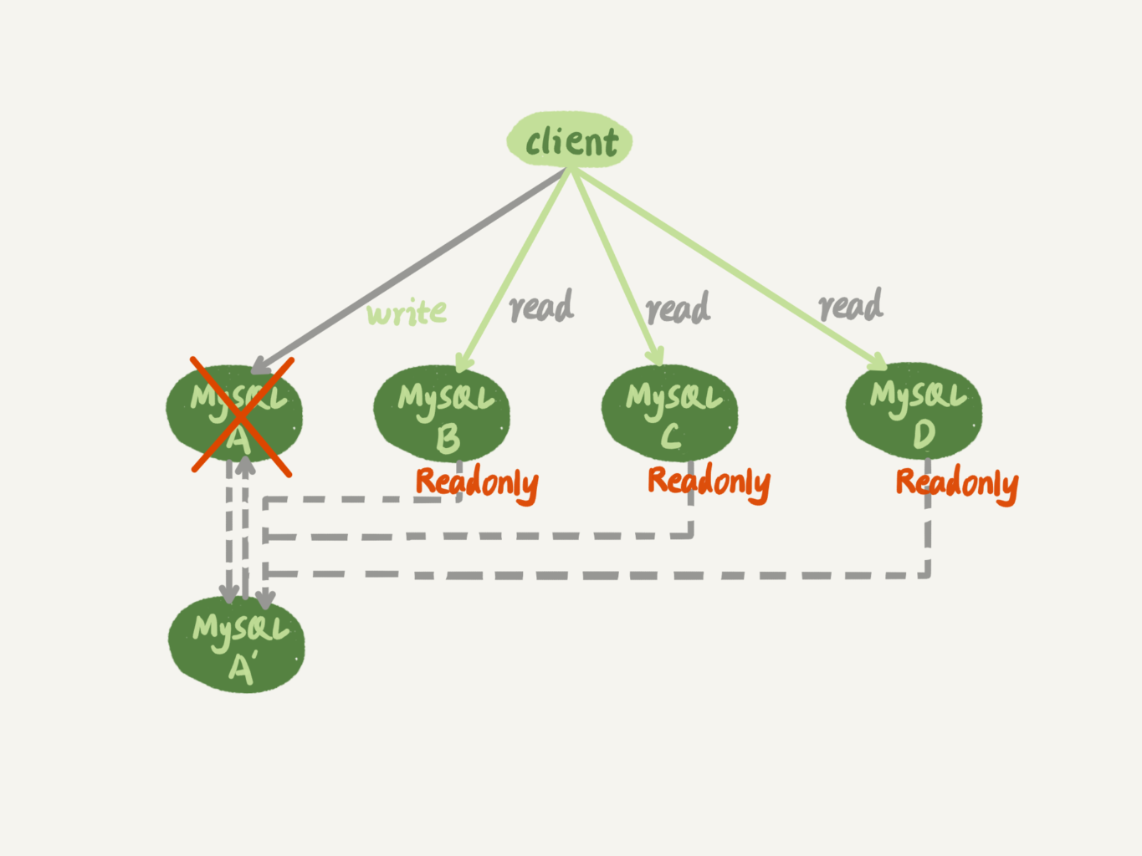
基于位点的主备切换
当把B置为A’的从库时候要执行如下命令
1 | CHANGE MASTER TO |
- host_name、port、user_name、password主库的IP、端口、用于主从同步的数据库用户名、密码
- master_log_name,和master_log_pos就是A’库binlog的文件名和位置成为位点;
原来的B是A的从库,所以B中记录的是A的位点,在change master之后,B要将位点置为A’的位点,由于A和A’记录的位点不一样,所以要大概估算出一个靠前一点的位点,在忽略掉主从不同步的情况。为什么要靠前一点的主要是有下面这种情况,下面语句是分析mysqlbinlog找到位点
1 | mysqlbinlog File --stop-datetime=T --start-datetime=T |
在A插入了一行R,同时同步给B和A’这时候A出现故障,B和A’都已经有了R行数据,如果这时候changemaster会提示主键冲突,停止同步。
解决的方案:
- 主动跳过1个事务,如下的命令,每次遇到这样的错误都跳过知道最后没有错误为止
- 通过设置slave_skip_errors参数,直接跳过指定错误,常见的错误如下,可以直接跳过“1062,1032”
- 1062 错误是插入数据时唯一键冲突;
- 1032 错误是删除数据时找不到行。
1 | set global sql_slave_skip_counter=N; |
注意:前提是这俩种操作是对业务无损的。
GTID– since v5.6
基于位面做主从切换比较复杂且很容易出错,所以mysql在5.6后引入了gtid彻底解决了这个问题。
GTID全程是Global Transaction Identifier,即全局事物ID,即一个事物提交后生成的全局唯一ID,他有俩个部分组成
GTID=server_uuid:gno(官方定义:GTID=source_id:transaction_id)
其中:
- server_uuid是mysql的实例ID
- gno是一个递增的整数,
如何启动gtid呢?
1 | gtid_mode=on |
下图就是我在主库上执行了一条插入看到的binlog,其中SET @@SESSION.GTID_NEXT= ‘b01b34d1-25cf-11e9-8e68-9ec1c2413262:1’就是这条事物的GTID
1 | mysql> show binlog events IN 'mysql-bin.000028'; |
gtid的分配方式:
- 当gtid_next=automatic时候,代表使用默认值:
- 记录binlog时候先记录一行SET @@SESSION.GTID_NEXT=
- 把这个gtid加入到本地实例的gtid集合中(Executed_Gtid_set)
- 如果gtid_next=是一个指定的gtid值时候,比如通过set gtid_next=’current_gtid’指定为当前的current_gtid时候,
- 如果current_gtid已经存在于gtid集合,接下来执行这个事务会跳过这个事务;
- 如果current_gtid不存在于gtid这个集合中,将这个current_gtid分配给新的事务,说明系统不需要分配新的gtid,gno也不需要加1
gtid的使用方法
加入一个库X是有一条数据(1,1),他的的gtid=aaaaaaaa-cccc-dddd-eeee-0000000000000:1
同时X作为了Y的从库,Y写入了一条数据(1,1),他的gtid=aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10
我们在X上执行如下的命令
1 | #将X的gtid_next置为Y库的aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10 |
基于GTID的主备切换
执行如下命令注意,master_auto_position表示的这个主备关系支持GTID协议,我们之前的MASTER_LOG_FILE和MASTER_LOG_POS已经不需要指定了。
1 | CHANGE MASTER TO |
B通过CHANGE MASTER变为A’的从库,B的gtid_set为set_b,A的gtid_set为set_a,在start slave时候逻辑如下:
- A和B建立主备关系;
- B把set_b发个A’;
- A’计算set_a和set_b的差集,差集说明是B需要执行的binlog,同时判断A是否包含了这些binlog
- 不包含,直接报错,说明A已经把这些BINLOG删除了
- 如果全部包含,A’从自己的binlog里找出第一个差集中的binlog开始同步
- 之后从这个事务开始一直往B同步
这种方式,由之前通过位点同步的,由从库来决定从哪里同步,到主库通过获取从库的gtid来计算出从哪里开始同步。