mysql事务的隔离级别以及实现原理
事务基础
启动事务的几种方式
- 显式启动事务语句, begin 或 start transaction,提交是commit,回滚是rollback
- set autocommit=0,每个CURD都会启动事务且需要手动commit/rollback。
- 在实际使用用,我们一般不采用2这种方式启动事务。
如何查看mysql事务的隔离级别,下面说明事务的隔离级别是读提交
1 | show variables like 'transaction_isolation'; |
事务的几种隔离级别
mysql的事务隔离级别分为:读未提交、读已提交(RC)、可重复读(RR)、串行,他们具体表现如下:
- 读未提交:事务中每个查询语句都获取当前数据的最新值。
- 读已提交:事务中每个查询语句获取的都是其他事务提交后的相关数据的最新值,Oracle的默认事务隔离级别。
- 可重复读:Mysql的Innodb的默认事务隔离级别。
- 串行:每个事务需要一个一个的执行。
mysql事务隔离方式的实现方式(只讨论RC 和 RR)
mysql的事务隔离实现机制采用的是一致性读视图(consistent read view)。即Mysql在事务启动时对整个数据库拍了一个快照。
- RR是在事务开始时候创建一致性视图
- RC是在事务中的每条sql语句执行前执行
具体的实现逻辑如下:
- Innodb对没个每个事务会分配一个transaction id,该ID是严格自增的ID。
- Innodb中每行数据是有多版本的,每个版本的数据会包含一个row_txid。将修改成这个版本数据的transaction id赋值给row_txid。
- 这个版本不是物理存在的是虚拟的,即在一个事务中一旦发现该行数据不可见,则需要根据row_txid对象的事务+undolog找到可见的数据,具体见下面5。
- 当一个事务启动时候会,会维护一个数组,这个数组包含这个事务开始之后,这时候所有活跃的transaction id(所谓即未提交的事务)。数组的取值范围如下:低水位是当前事务中最小的transId,高水位数组中最大的transaction id+1;数组关系可见下图:
- 当这个事务去读数据时候,会有如下情况:
- 判断如果这条数据row tx_id<低水位,说明当前的数据在本事务创建前已经被提交过了,所以可见;
- 判断如果这条数据row tx_id>高水位,说明当前的数据在本事务创建之后被提交过了,所以不可见,需要通过undolog找回之前的版本;
- 判断如果这条数据row tx_id在数组区间,如果row tx_id是数组范围内的值,说明事务未提交过,所以不可见;发只,说明该数据是已经被其他事务提交生成的,所以可见;
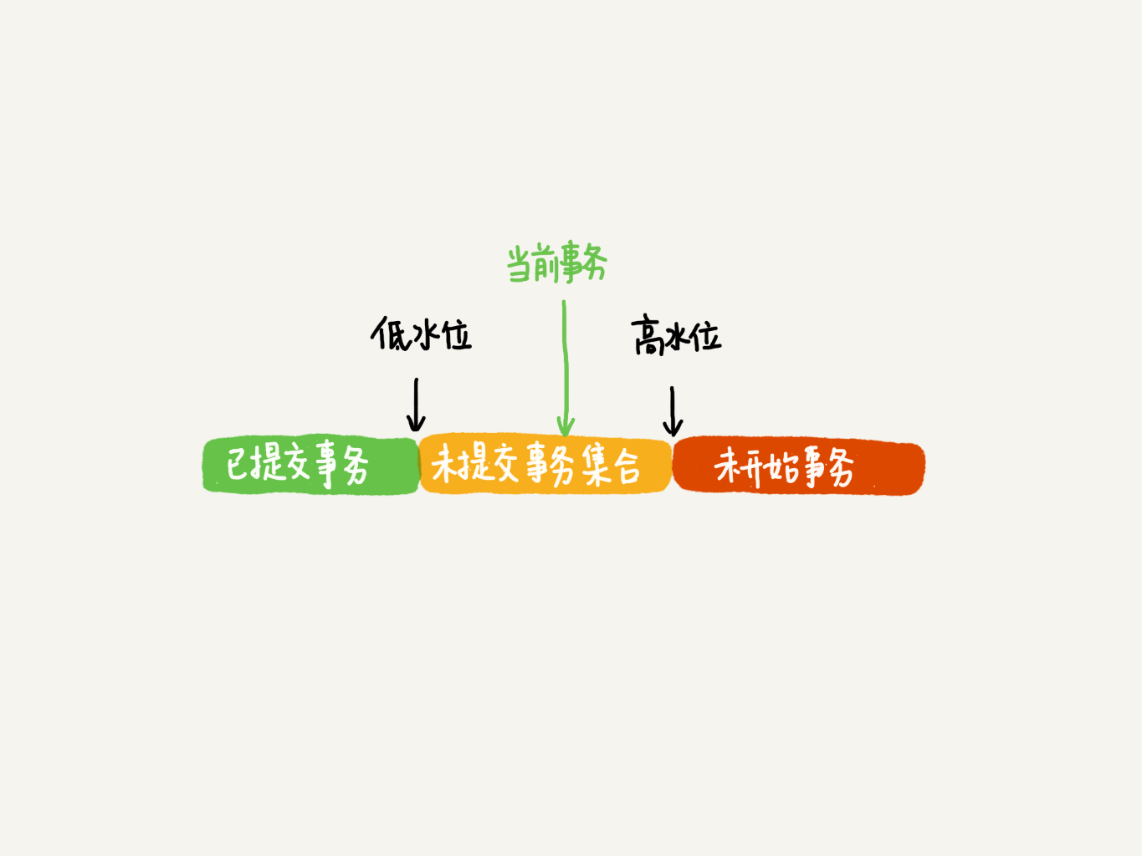
上面的规则比较拗口,翻译过来就是:如果数据的版本是先于本事务开始前生成的可见,如果后于本事务开始前生成的本可见。
mysql如何保证多个事务同时修改一条数据的准确性
思考下面问题:
1 | 因为mysql在update时候实际上是先select在更新,所以在RR隔离级别中。 |
答案是不会的。
因为mysql在修改时会遵循一个原则:读当前值,当更新数据时候都是先读后写,所以这时候值能读当前值。俩个事务同时更新一条数据的流程和原理如下:
- 当并发进行更新时,对数据进行加x锁,后面的更新操作会block住,直到其他的事务提交后才继续下去;
- 由于更新是当前读,所以数据被本事务被更新过后,由于row tx_id就是当前事务,所以读到的值是新的值;
隔离级别RR如此那RC呢
其实原理是一样的。只是RR是每一次事务开始时候创建一致性视图,而隔离级别RC则是在事务中每一条sql语句在执行前都要创建一个一致性视图,这样视图是动态的,每条sql语句根据上面提到的规则都要去确定数据的可见性。