NAT概念
NAT技术可以重写IP数据包的源IP或者目的IP,被普遍地用来解决公网IP地址短缺的问题。
原理:网络中的多台主机,通过共享同一个公网IP地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。你既可以在支持网络地址转换的路由器(称为 NAT网关)中配置NAT,也可以在Linux服务器中配置 NAT。如果采用第二种方式,Linux服务器实际上充当的是“软”路由器的角色。
根据实现方式的不同,NAT 可以分为三类:
- 静态NAT,即内网IP与公网IP是一对一的永久映射关系;
- 动态NAT,即内网IP从公网IP池中,动态选择一个进行映射;网络地址端口转换
NAPT(Network Address and Port Translation),即把内网IP映射到公网IP的不同端口上,让多个内网IP可以共享同一个公网IP地址。
我们基本上都会采用NAPT。
根据转换方式不同,我们又可以把NAPT分为三类。
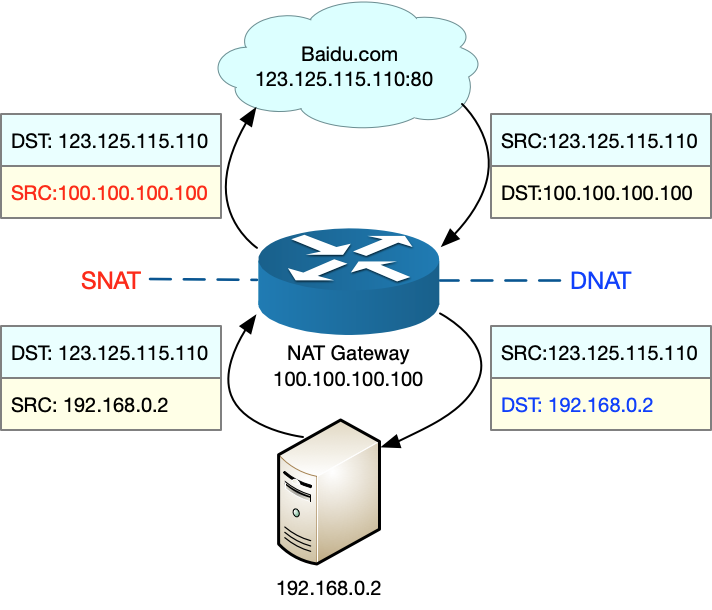
SNAT,即目的地址不变,只替换源IP或源端口。SNAT主要用于,多个内网IP共享同一个公网IP ,来访问外网资源的场景。
- DNAT,即源IP保持不变,只替换目的IP或者目的端口。DNAT 主要通过公网IP的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实IP地址。
双向地址转换,即同时使用SNAT和DNAT。当接收到网络包时,执行DNAT,把目的IP转换为内网IP;而在发送网络包时,执行SNAT,把源IP替换为外部 IP。
这3种方式如图
iptables和NAT
我们可以通过设置iptables来做NAT的映射,其中:
POSTROUTING:在经过路由之后,用来设置SNAT
PREROUTING:在经过路由之前,用来设置DNAT
1 | # POSTROUTING 经过路由 设置-s realServer内网IP -j SNAT --to-source 外网IP |
NAT影响性能的原因
测试步骤
- 在服务器上运行nginx-docker,使用HOST网络,不使用NAT,用ab测试观察每秒请求书,请求平均延迟,建立连接访问延迟
- 在服务器上运行nginx-docker,使用NAT,用ab测试观察每秒请求书,请求平均延迟,建立连接访问延迟。
1 | docker run --name nginx-hostnet --privileged --network=host -itd feisky/nginx:80 |
NAT的工作原理:网络包的流向以及NAT的原理,你会发现,要保证NAT正常工作,就至少需要两个步骤:
- 利用 Netfilter 中的钩子函数(Hook),修改源地址或者目的地址。
- 利用连接跟踪模块 conntrack ,关联同一个连接的请求和响应。
通过SystemTap来追踪内核
我们编写如下脚本,之后执行 stap –all-modules dropwatch.stp 将脚本编译进内核状态
1 | #! /usr/bin/env stap |
再进行ab压测发现丢包都发生在nf_hook_slow
整个请求的原理如下,我们知道了原理,可以有针对的进行性优化,调整内核参数。
- 接收网络包时,在连接跟踪表中查找连接,并为新的连接分配跟踪对象(Bucket)。
- 在 Linux 网桥中转发包。这是因为案例 Nginx 是一个 Docker 容器,而容器的网络通过网桥来实现;
- 接收网络包时,执行 DNAT,即把 8080 端口收到的包转发给容器。
1 |
|
附录
conntrack工具查看链接表内容
1 | # -L表示列表,-o表示以扩展格式显示 |
dmsg查看系统错误日志