C10K的C只的是client客户端的意思,意思是支持1W的客户端连接。C1000K则是指100W的客户端连接。为了达到C10K,我们就要对系统进行优化,一般会从俩方面考虑。
IO方面的优化
因为传统的BIO一个线程只能同时处理一个IO请求效率比较低。为了增大并发处理的能力,我们往往会采用IO多路复用的思路去解决问题。I/O多路复用是什么意思呢?
我们先来普及俩个概念
- 水平触发:只要文件描述符可以非阻塞地执行 I/O ,就会触发通知。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行 I/O 操作。
- 边缘触发:只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才发送一次通知。这时候,应用程序需要尽可能多地执行 I/O,直到无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
select或者pool的水平触发
select 和 poll 需要从文件描述符列表中,找出哪些可以执行I/O ,然后进行真正的网络I/O读写。由于I/O是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的。【多路复用指的就是粗体部分】
缺点:
- select采用标量位,32位系统默认只能支持1024个描述符,且select的fd的状态位是也是用标量位来表示的,获取每个fd的状态需要轮询这个标量位。时间复杂度是o(n^2)
- pool采用了个无界数组,没有了1024的限制,时间复杂度是o(n),但是他俩都需要将能读写的fd,从用户态转移到内核态修改状态每次都要进行切换会造成损耗
epool的边缘触发
epool采用红黑树管理fd,时间复杂度o(log2n),epool在内核态管理fd没有切换的损耗。
系统并发度方面的优化
master+worker的方案,nginx或者我们的netty架构几乎都是这种方案master和worker可以是进程也可以是线程。这种情况要考虑避免惊群效应,即多个进程被同时唤醒,但实际上只有一个进程来响应这个事件,其他被唤醒的进程都会重新休眠、
- 其中,accept() 的惊群问题,已经在 Linux 2.6 中解决了;
而epoll的问题,到了 Linux 4.5 ,才通过EPOLLEXCLUSIVE解决。
Nginx是如何避免惊群问题, Nginx在每个worker进程中,都增加一个了全局锁(accept_mutex)。这些worker进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到epoll中,这样就确保只有一个worker子进程被唤醒。
监听到相同端口的多进程模型。在这种方式下,所有的进程都监听相同的接口,并且开启 SO_REUSEPORT 选项,由内核负责将请求负载均衡到这些监听进程中去。这一过程如下图所示
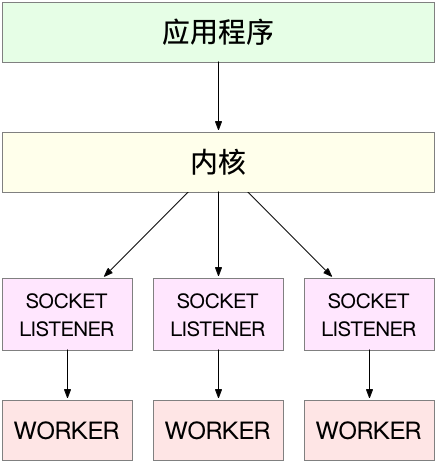
这由于内核确保了只有一个进程被唤醒,就不会出现惊群问题了。比如,Nginx在1.9.1中就已经支持了这种模式。
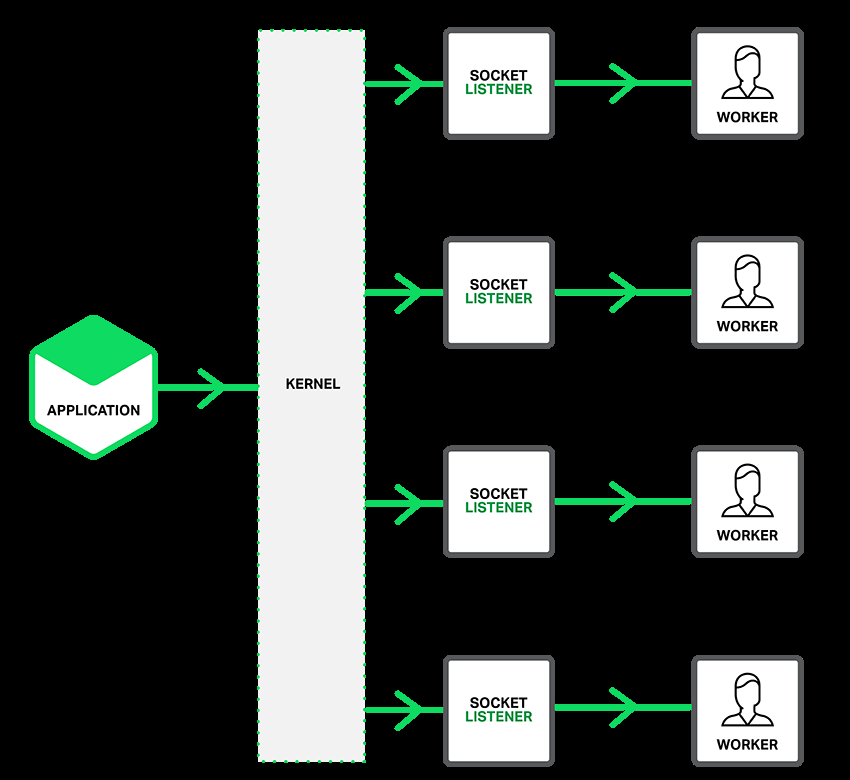
我们从C10K-C100K都可以用这种方案+不断升级我们的硬件来解决。但是到了更高C1000K因为中断、网络包链路过长等等原因采取一些新的手段比如
DKDP
允许我们在用户态直接处理请求包并且调用网卡发送出去,需要支持DKDP网卡

XDP
允许我们在进入网络协议栈之前先处理网络包
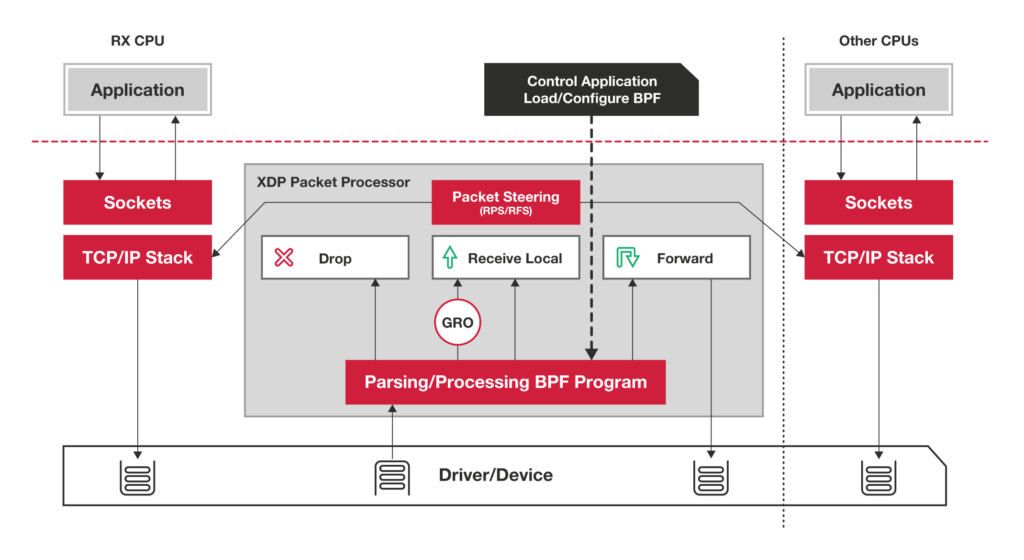
但是:其实我们C10K就几乎够用了因为我们还要考虑业务等因素,我们还是推荐拆分到不同的服务器中。