跳表
- 数组的特点是支持随机访问,随机访问方便,但是插入、删除、修改比较麻烦【时间复杂度是O(N)】
- 链表的特点是不支持随机访问【时间复杂度是O(N)】,但是插入、删除、修改比较方便【时间复杂度是O(1)】
如果业务在效率上要兼顾随机访问和修改,是否有好的方案呢,就是我们今天的主角–跳表(skiplist),甚至在某些方便可以取代红黑叔
跳表的原理以及事件复杂度
原理
跳表的底层依赖是链表,但是在链表上层加了索引层。每个节点都包含一个down指针,索引层的节点的down指针指向下一层的节点,如图: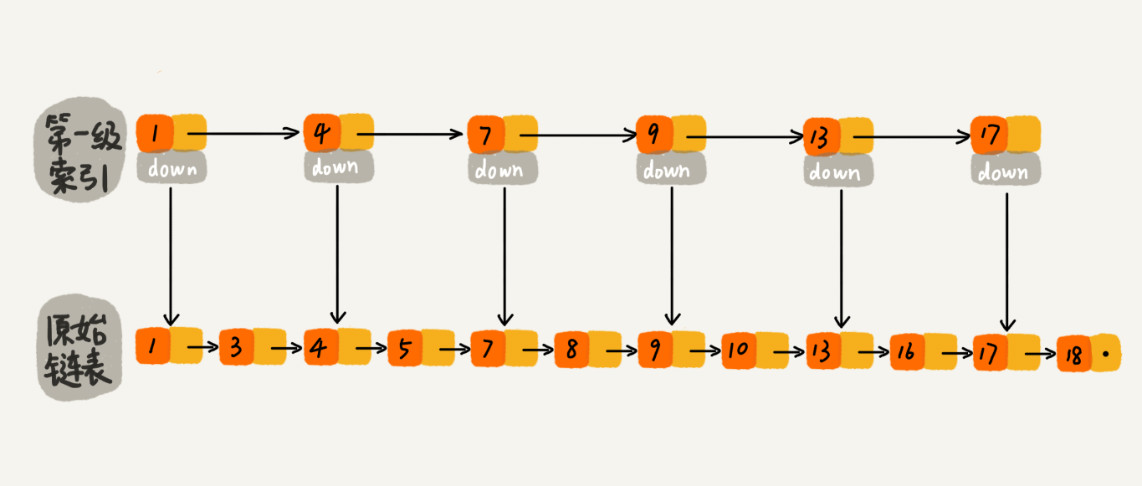
查找时候先从上遍历索引层确定范围,然后通过down指针逐层在缩小的数据范围内找到数据。
复杂度
时间复杂度
查询:O(mlogN),m是每层遍历都少个节点
修改:O(logN)
空间复杂度
O(n):由于链表增加了索引层,索引层一般是一个等比数列,比如说:没2个节点建立一个索引,所以空间复杂度是n/2+n/4+n/8+n+4+2=n-2。
跳表最坏情况
动态更新如果增修改数据层,或者添加不平很会导致跳表退化成链表如图,所以需要一个随机函数,随机的将节点添加到任意一层索引层,比如随机函数生成了k,要讲节点添加到1~k层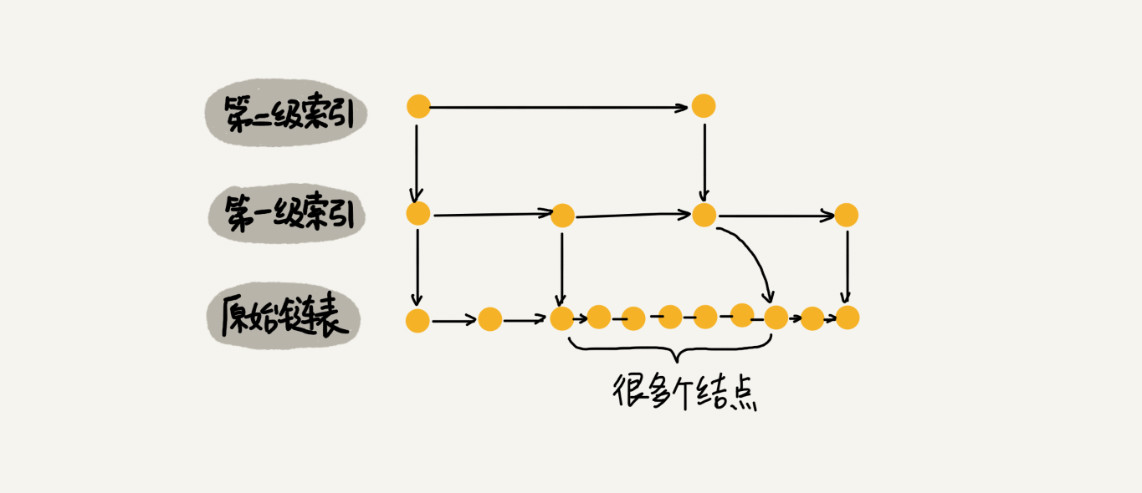
使用场景
数据有序、能利用到2分发对数据进行查找、同时兼顾修改的效率(redsi的sortSet)。