搜索引擎分为如下四个部分
爬虫抓取
- 利用graph的bfs方式遍历,每个url就是一个vertex,用links.bin作为bfs搜索的队列,这样支持断点续排,并且也能减少内存的使用
- 由于网页的量巨大,我们可以用bloomfilter进行排重,这样能减少内存空间,即bloomfilter.bin
- 保存原始网页docs_row.bin,格式是docs_id–>docs_content,docs_id由一个中心计数器生成
分析
- 抽取文本信息:去掉网页中的标签等信息 可以理由ac自动机
- 创建临时索引:然后对文本进行分词
- 创建tmp_index.bin,格式是:term_id–>doc_id
- 创建term_id.bin,格式是:term_id–>term (散列表)
- term_id通过一个中心计数器生成
索引
- 分析网页,简历倒排索引:即term_id–>doc_id1,doc_id2,doc_id3。由于临时索引很大,我们可以采用多路归并排序(map-reduce)进行归并,index.bin
- 记录term在倒排索引偏移量的文档term_offset.bin
如图: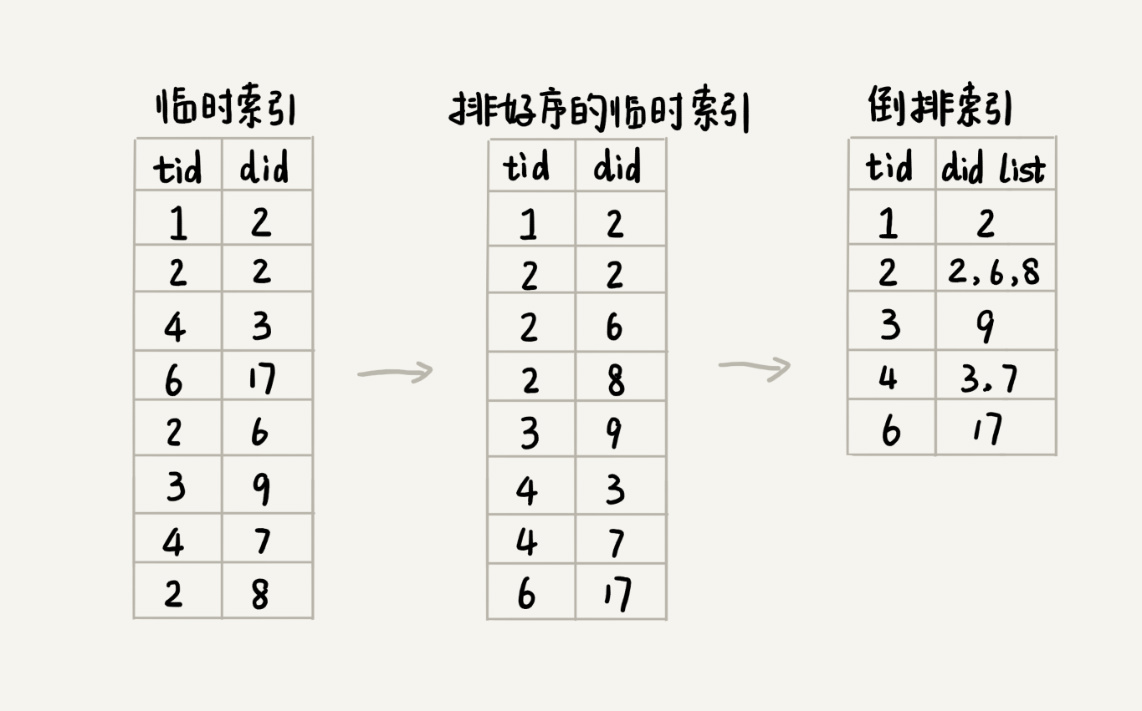
查询
我们通过上面提到的文件:term_id.bin、term_offset.bin、index.bin、docs_id.bin,
- 想通过且此获取k个term
- 在通过term_id.bin获取term_id
- 在通过term_offset.bin找到索引中对应的doc_id,看那个doc_id出现的次数最多就说明哪个服务客户需要就排在前面
- 按照3的顺序在docs_id.bin查找顺序。
摘要实现原理
我们在创建临时索引时候可以将摘要和doc_ic以及term_id存入到schema.bin中,需要的时候查询出来。
网页快照可以将doc_id–>doc_row用lru的算法存入到shap_shot.bin中。