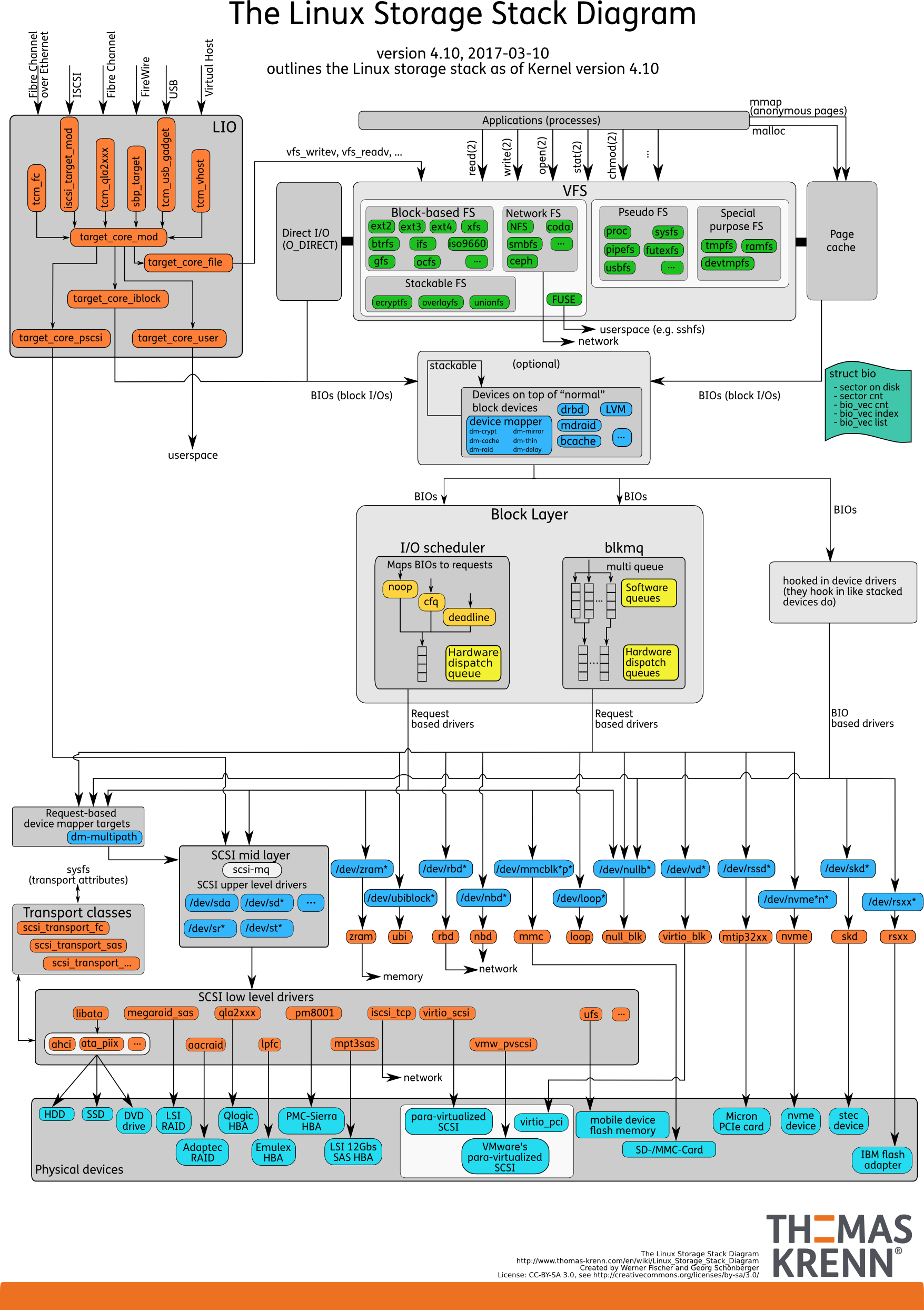
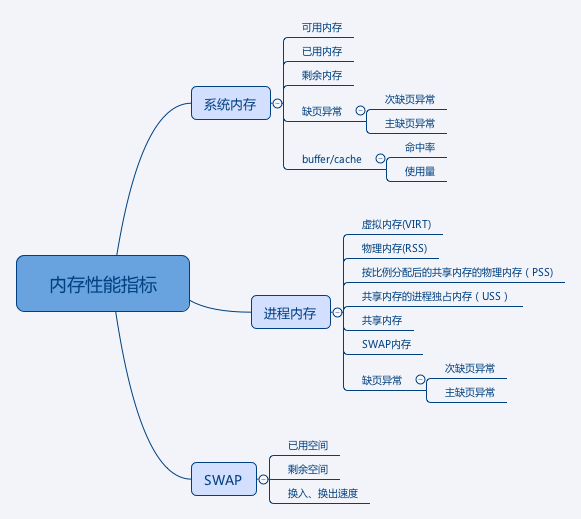
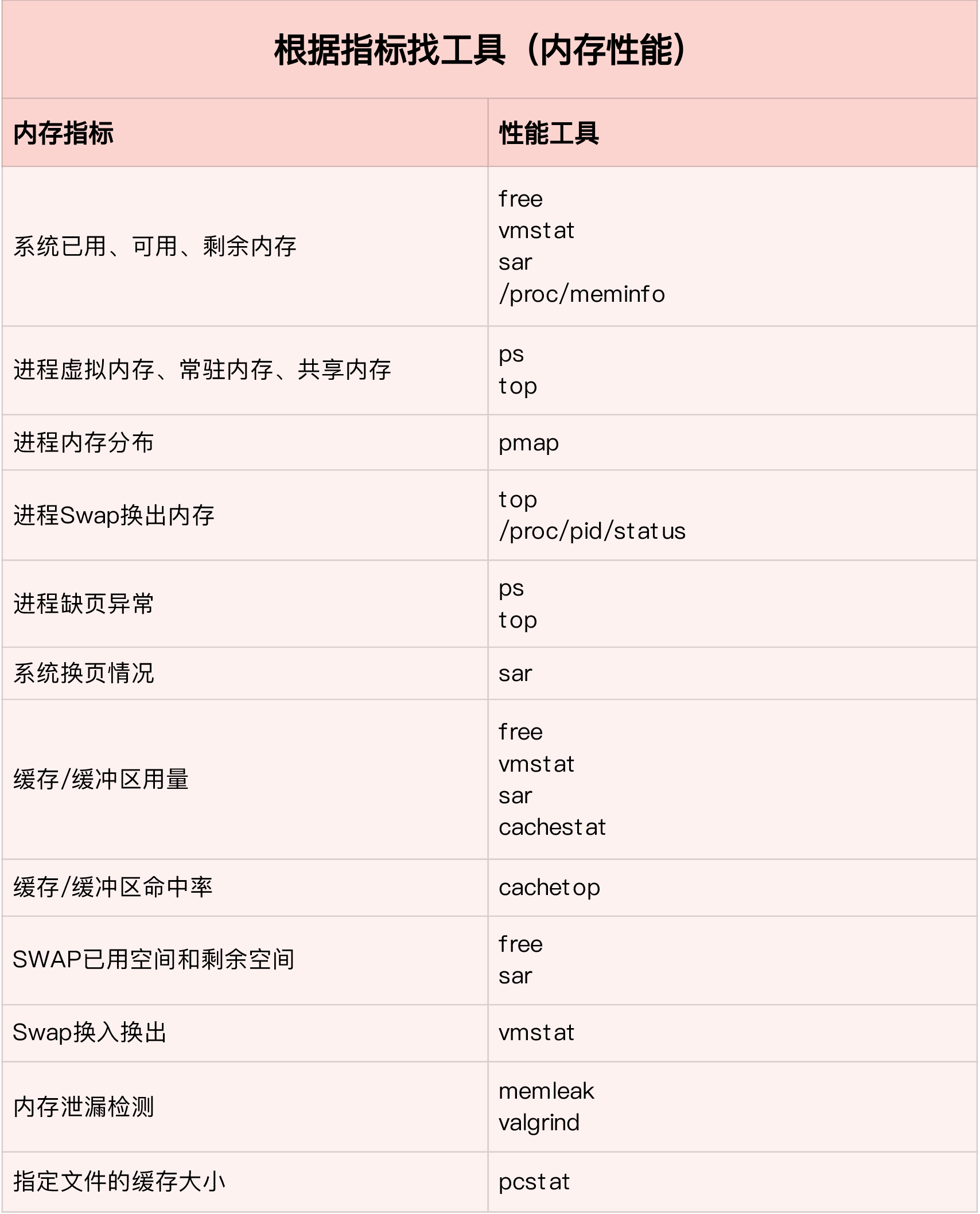
案例准备:启动一个web应用,用另一个中端请求,发现响应极慢
1 | docker run --name=app -p 10000:80 -itd feisky/word-pop |
1 | curl http://192.168.0.10:1000/popularity/word |
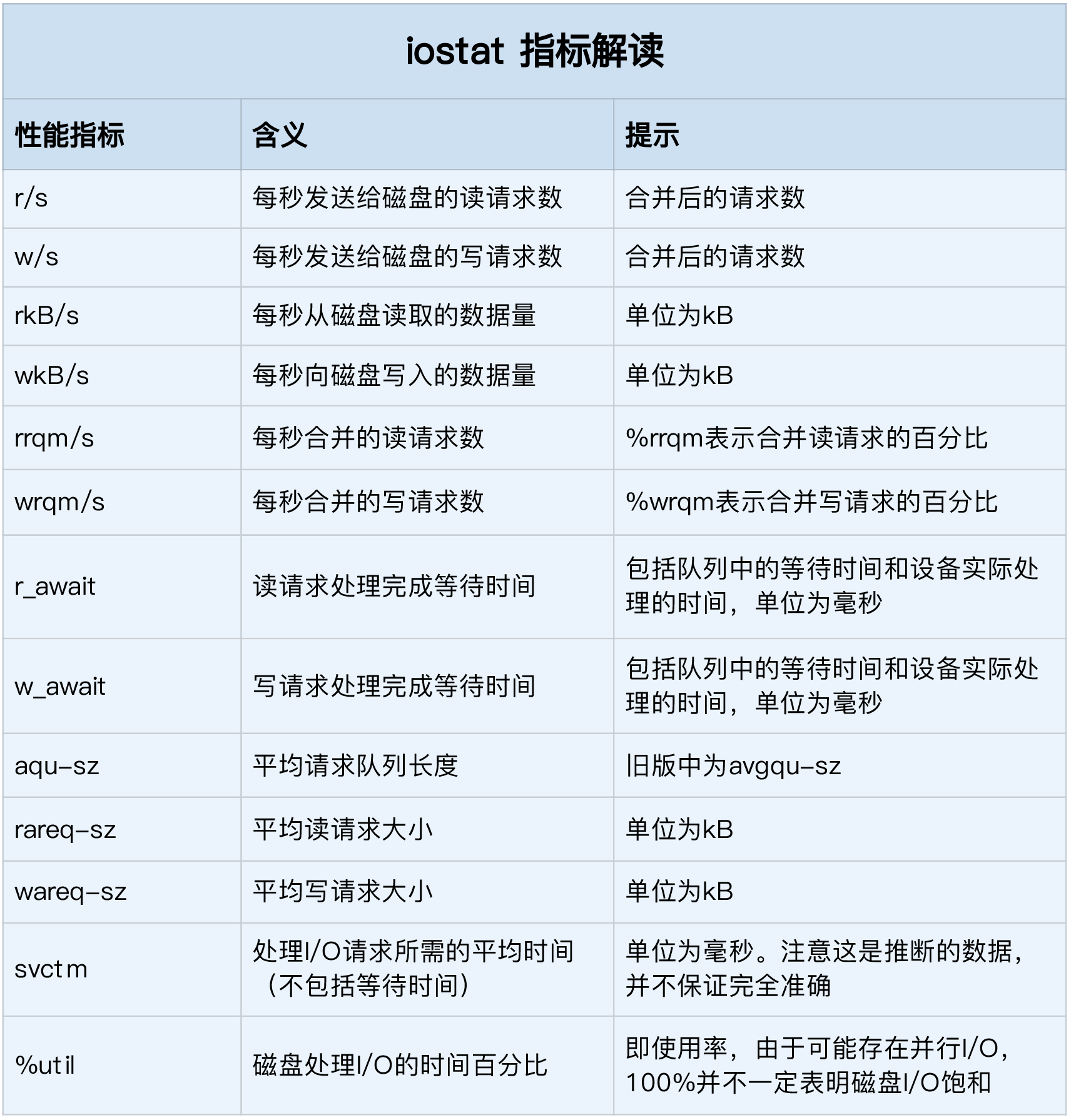
top、iostat发现磁盘的io很高,用strace的套路查看代码发现没有write的痕迹,这时候我们可以用bcc-tools下的filetop查看
1 | # 切换到工具目录 |
我们可以看到 线程ID,命令,读/写的次数、大小,文件类型,文件名称找到了创建了xxx.txt文件,我们通过ps找到tid所属的进程
1 | ps efT|grep 514 |
在通过bcc下的opensnoop找到具体的文件
1 | $ opensnoop |
猜测是程序接到请求后,创建了一堆临时文件,在读取到内存,然后删除了文件导致的,修改程序问题解决。