MySql是如何降低主备延迟的
上一章MySQL是怎么保证高可用的,中提到了主库的并行复制能力会影响主备的延迟。在mysql5.6之前,rely_log被sql_thread重放写入备库,这里的sql_thread只能单线程消费,所以会很大程度降低mysql数据库的吞吐,在TPS高的时候就会有很大的延迟。如果想增强吞吐就要多sql_thread并行处理relay_log,如图:
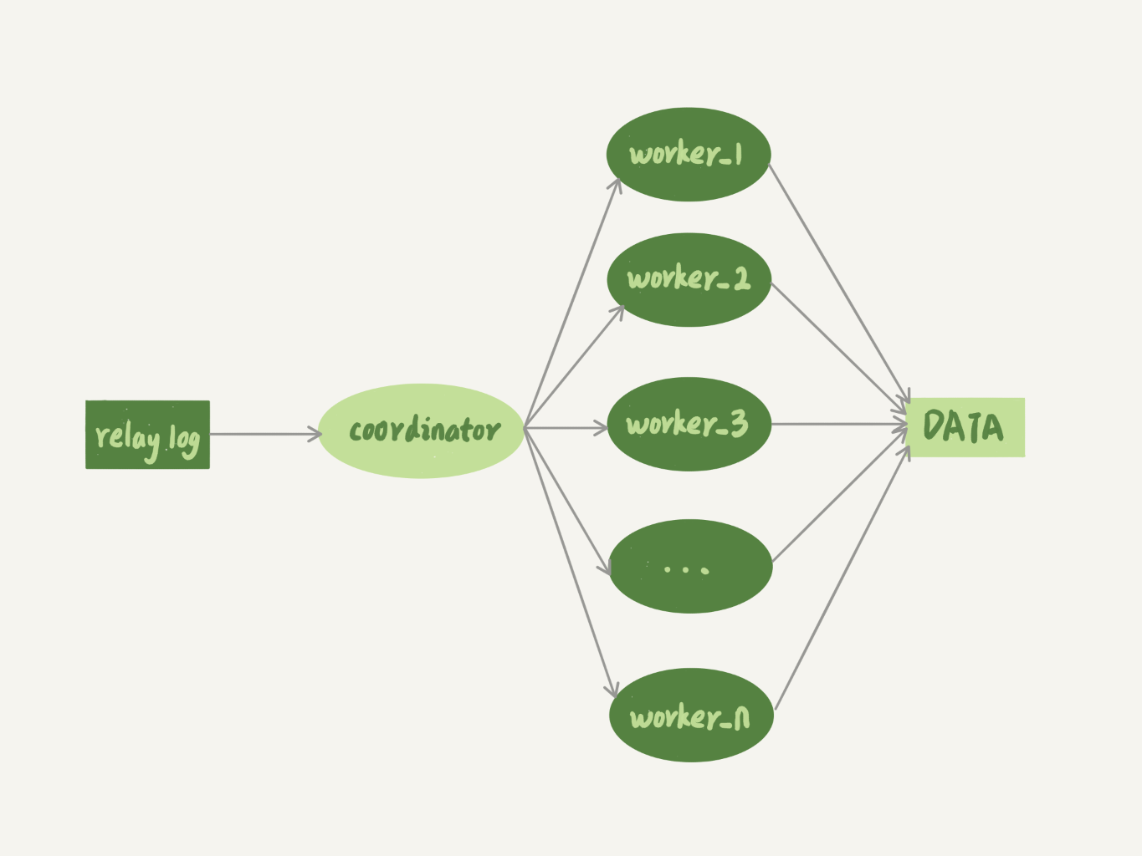
但是mysql并行的主从并行复制要遵守如下原则:
- 对于不同的事务的binlog如果修改同一行数据,为了避免相互覆盖,不能并行运行只能串行
- 对于相同事务的binlog,为了保证事务的完整性,不能并行复制,
5.5之前的主从复制策略
在5.5的时候,为了增强mysql的从库消费relay_log的吞吐,使用者自己实现了主从复制的策略主要有俩种:
按表并行复制
- 每个work维护一个hash_table,key是binlog的dbname+tablename;
- 当一个binlog分配给coordainator,coordainator会循环检查这个binlog的key(dbname+tablename),是否在work的hash_table中,如果出现说明这个binlog和这个worker冲突;
- 如果只有一个冲突,交给这个work处理;
- 如果大于一个冲突,coordainator进入等待;
- 如果没有冲突,交给空闲的worker处理;
- 当worker处理完后会把key从hash_table中删掉;
按行并行复制
和上面类似,只不过这次并行控制的粒度更细,只要保证binlog不是修改的同一行数据即可并行复制,那么hash_table的key就变为binlog的dbname+table+唯一健的值(主键+唯一索引),光有主键不够一定要带上唯一索引的值,否则如下情况会报唯一建冲突。
注:c=原有的值是1,当备库并行复制时候先执行sessionB,由于这时候sessionA还没执行,会报唯一建冲突
| sessionA | sessionB |
| —— | —— |
| update t set c=5 where id=1 ; | - |
| - | update t set c=1 where id=1; |
缺点
- 必须要能通过解析binlog获取dbname,tablename,pk,uniqekey,所以binlog要是row类型;
- 必须有主键;
- 不能有外键;(因为外键的级联更新不在binlog中,所以建冲突就不准确)
- 按表的策略:在对热点表的时候coordainator会频繁进入等待,又变成了单线程复制;
- 按行的策略:要计算hashtable的key需要额外解析pk和uniquekey所以需要额外的开销;
Mysql5.6的并行复制策略
按照库名并行复制
优点:
- 构造hash很快,只需要库名;
- binlog即使不是row也能很方便获取库名;
缺点:
- 若果服务器上只有一个库,优化效果不明显;
MariaDB的并行复制策略
它的思想是思想是模拟主库运行:利用group commit,每一组事务能同时提交一定是不冲突的;那么主库commit之后就将一组的binlog一起并行执行
- 为每个group commit分配个递增的commit_id;
- 将commit_id写入到binlog中
- 同一个commit_id的binglog分到不同的worker上去。
- 执行完这个commit_id后在执行下一个commit_id的binlog。
缺点:
- 并不是真正的象主库并行,主库当一组事物在commit阶段时候,下一组事物是在运行中的。而从库消费的时候只能是一组一组的消费,所以还是会造成主备的延迟。
- 当一组有一个很大的事物在worker中运行时候看,其他的worker先运行完了也只能等在哪里。
MySql5.7的并行复制的策略
采用类似的MariaDb的类似的赋值策略由slave-parallel-type参数控制:
- DATABASE时候采用类似5.6的并行复制策略
- LOGICAL_CLOCK时候采用MariaDb的并行复制策略,但是做了优化;
和MariaDb相比,将binlog的执行时期从commit阶段放到了2PC的redolog的prepare阶段,mysql认为事物进入prepare阶段就说明数据是可靠的可以进行主从复制了。
- 同时处于 prepare 状态的事务,在备库执行时是可以并行的
- 处于 prepare 状态的事务,与处于 commit 状态之间,在备库执行时也是可以并行的。
我们可以通过binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay参数故意拉长主库的binlog从write到fsync的时间,减少binlog的写盘次数,制造更多同时在prepare时期的binlog,加大并行度。
MySql5.7.22的并行复制优化
增加参数binlog-transaction-dependency-tracking。
- COMMIT_ORDER:和上面说的策略一样;但是如果是追历史数据还是会退化成单线程,所以适合线上库。
- WRITESET:对于事务更新的每一行计算hash值,组成集合writeset,如果俩个事务没有操作相同的行,也就是writeset没有交集,就可以并行。
- WRITESET_SESSION:多了一个约束,即在主库上同一个线程先后执行的事务,在从库上也要保证同样的顺序。
和之前5.5的按行并行复制策略很类似但是有几点优化:
- hash值提前算好了,减少了主从同步时候的压力;
- 不需要在从库每次都把所有woker遍历一遍找出是否冲突;
- 备库不用解析binlog对备库的binlog格式无要求;
思考如下:
假设一个 MySQL 5.7.22 版本的主库,单线程插入了很多数据,3小时候,搭建从库开始同步数据binlog-transaction-dependency-tracking改如何设置?
答:建议采用 WRITESET,因为是单线程插入,如果采用WRITESET_SESSION,那么会退化成单线程同步relaylog。COMMIT_ORDER因为是追历史数据,所以会退化成单线程