JIT(java in time complier),即为了提高热点代码效率将代码编译成本地代码。
解释器与编译器
HotSpot采用的是解释器与编译器共存。
解释器可以发挥编译优势,省去编译成本地代码的时间,直接运行;编译器把反复执行的代码编译成本地代码提高执行效率。同时如果编译器的优化比较激进发现编译后的结果不成立可以通过解释器退回到之前状态。
解释器和编译器这种搭配方式称为混合模式。可以通过-Xint来控制
俩个编译器ClientComplier和ServerComplier
ClientComplier注重编译速度,ServerComplier注重编译的质量。HotSpot在JDK1.7时代默认采用分层编译
- C0:解释执行
- C1:将字节码编译成本地代码,简单的优化。
- C2:会启用一些耗时优化。
出发条件
HotSpot采用基于计数器的方式。
- 方法的重复调用
- 条件:重复一定次数(方法调用计数器控制)
- 方式:调用次数+1.触发阈值后发送编译请求。编译完成后替换方法地址
- 半衰周期:当一段时间没到阈值会,方法调用计数器会衰减一半
- 默认值:client:1500,server:10000
- 循环体的调用:OSR(on stack replacement)栈上替换,发生在运行时的方法栈
- 条件:重复一定次数(回边计数器)
- 方式:以方法为单位如果,每一次循环回边计数器都+1,如果回边计数器和方法调用计数器超过一定数值后发送编译请求。(这时候重新调整计数器以便继续循环)编译完成后替换方法地址
编译过程
后台编译
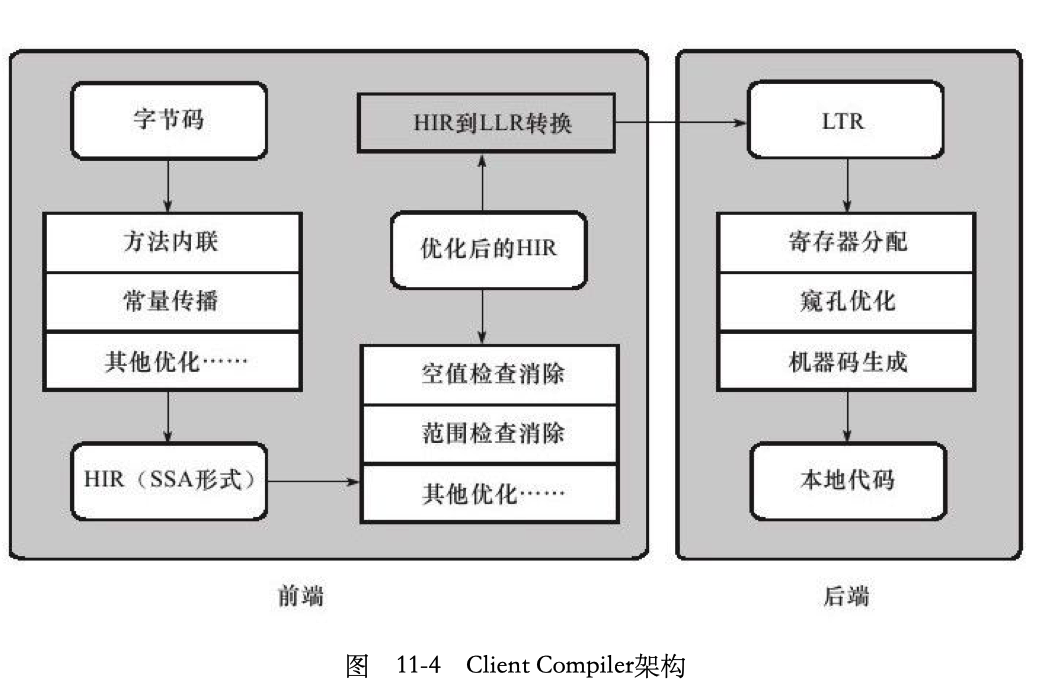
具体的HIR LIR我也没太看明白以后看编译原理在不上:P
编译优化的技术
编译代码比解释代码优化,一方面是没有虚拟接解释代码的消耗,一方面是所有的代码优化措施都集中在JIT上。
优化技术概览


公共子表达式优化
比如程序有俩个bc和cb,javac不会进行优化,java则会优化成E=b*c,然后代码使用E
异常消除
NullPointer,ArrayIndexOutOfBounds等异常信息,在运行时如果不优化每次判断都会带来开销,所以jit会对齐进行优化,消除这些隐式的判断。而且会根据Profile收集到的信息进行“智能”优化。比如一个对象经常为空的情况就不回采用try catch的优化。
方法内联
由于JAVA是面向对象的,很对方法是虚方法,为了优化就采用CHA,如果是虚方法会去查询有几个版本如果只有一个版本会进行内联,如果继承关系发生改变,比如动态代码,这时候要退回解释执行。如果发现多个版本还会采用Inline Cache来尝试内联
逃逸分析
栈上分配、同步消除、标量替换